Why you need to have reliable data
Your ability to increase your visibility in AI Search is only as good as the data used to track it.
Promptwatch has built a reputation of having actionable data that's trusted and easy to interpret. The reason for that is because how we collect our data.
We collect our data by scrapping the UI interfaces of the LLMs used everyday by hundreds of millions of people. This includes ChatGPT, Gemini, AI Overviews, Perplexity and others.
How Promptwatch collects data
Our process is done in the following steps:
1. Browser activity is automated the same way a user would when they access an LLM and entering the prompt just as its entered into our platform.
2. Once the LLM gives its response, our automation scrapes both the prompt, responses, and citations in the conversations.
3. This response is then entered into your dashboard so you can see how the different models respond to your prompts
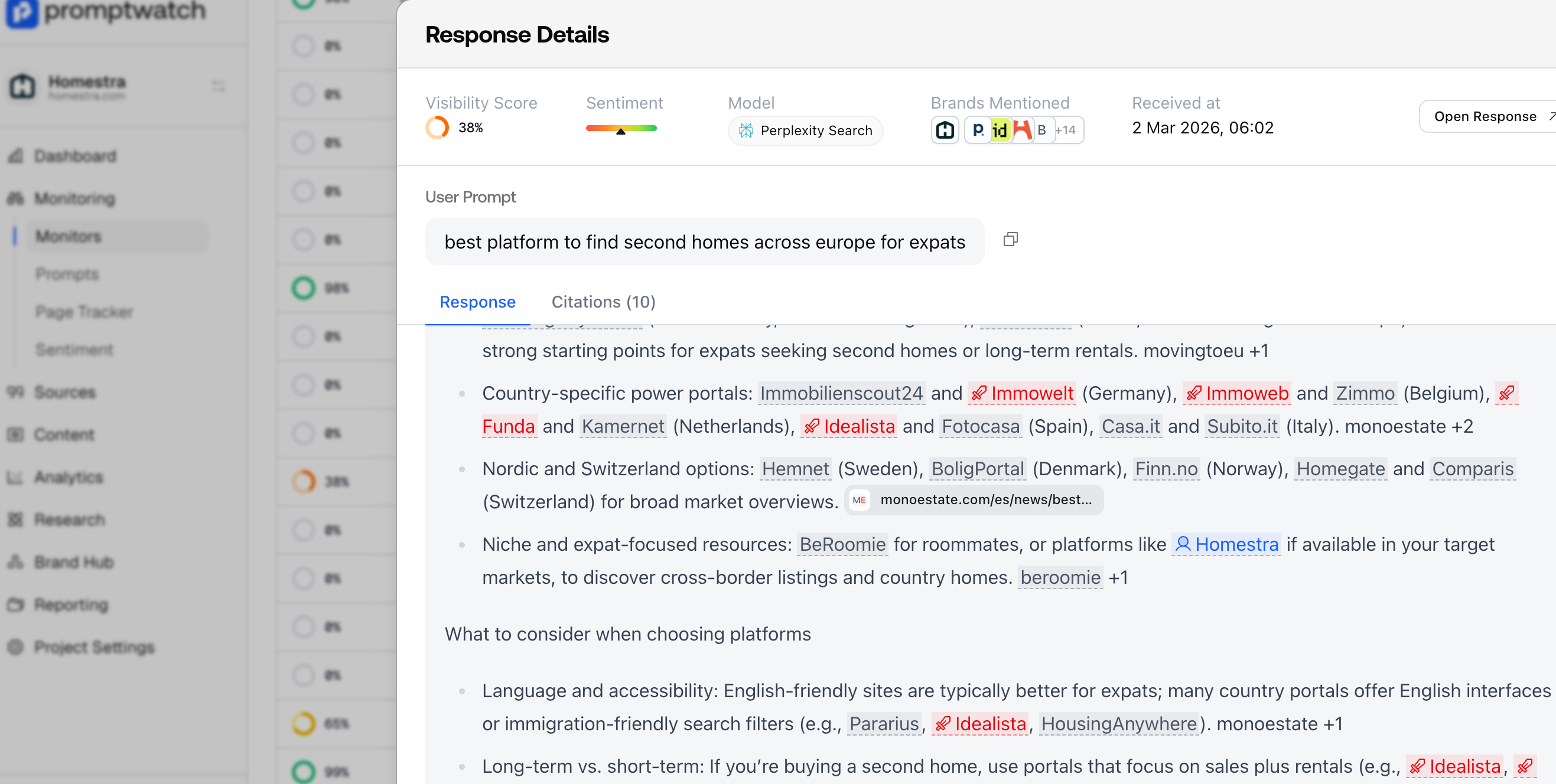
4. We repeat this process daily, on all models and in all languages you have set.
Import to note: UI Scraping is what allows us to give you insights into, multiple languages, regions, enrichments such as “ChatGPT Shopping” and if images or tables were used in responses.
Dangers of using API responses
Most AI Visibility tools connect to the API of LLMs like ChatGPT, Gemini, Perplexity, and others. This is not the way you want your prompts to be monitored as the APIs act completely different from the browser interface that users interact with on a daily basis. How to spot if a tool is using the API:
- You won’t be able to get insights into ChatGPT Shopping or if images and other enrichment were used in responses
- Responses to your prompts will seem repetitive
- Something goes wrong with the platform when a new version of the API is released from the LLM


