We grew a new domain's daily citations in AI search (ChatGPT, Perplexity, Claude, and Copilot) from roughly 200 to over 1,700 in about 90 days. We did it with a simple, repeatable loop: build a structured prompt strategy, analyze the query fan-outs for recurring sub-questions, then publish content that answers those sub-questions directly and optimize anything that fails to get cited. This step-by-step guide breaks down the exact process so you can run it yourself.
What does it mean to grow AI citations?
An AI citation is an instance where a large language model (LLM) references your page as a source while generating an answer. When someone asks ChatGPT or Perplexity a question and the model pulls a fact, quote, or link from your site, that's a citation. Citations are the AI-search equivalent of a ranking — except instead of competing for a position on a results page, you're competing to be part of the answer itself. (For a fuller breakdown of how brand mentions in AI work, see our guide on how to get your brand mentioned by AI.)
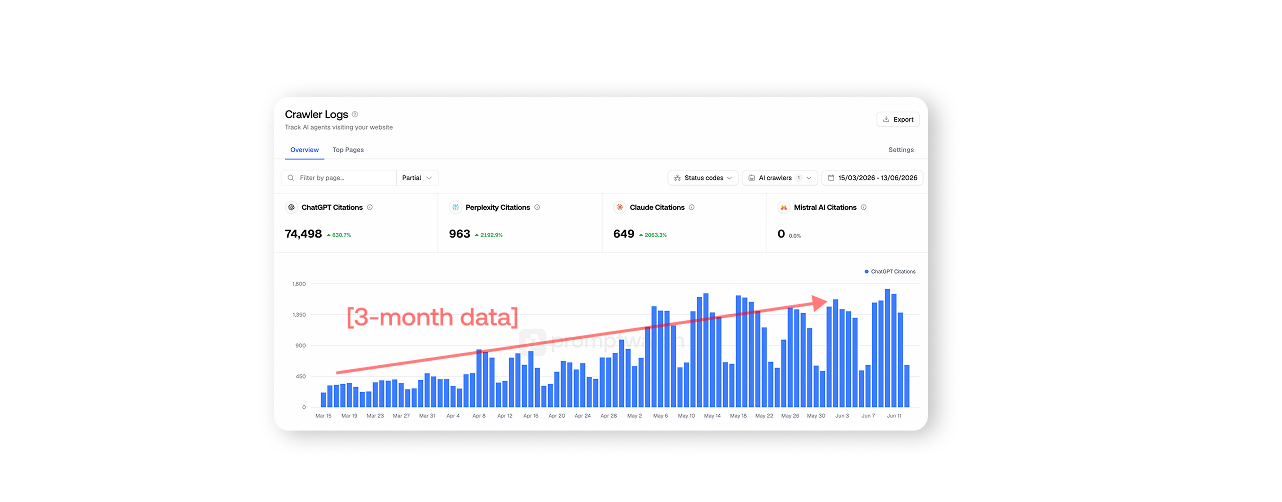
Growing citations means increasing how often, and for how many distinct prompts, LLMs draw on your content. On a brand-new domain with no authority and no backlink history, we took daily citations from around 200 to more than 1,700 — a roughly 630% increase — without buying links or publishing at high volume.
The short version of how: we stopped optimizing for keywords and started optimizing for the sub-questions models actually resolve before they answer.
Why is getting cited in LLMs different from ranking in Google?
Traditional SEO optimizes for a ranked list of links. A user types a query, Google returns ten blue links, and you compete for a click. The content that wins is shaped by keywords, backlinks, and on-page signals tuned over two decades.
Generative engine optimization (GEO) works differently. An LLM doesn't hand back a list — it composes a single answer and decides which sources to build that answer from. According to several studies, GEO strategies can lift a page's visibility in generative responses by up to 40%. To compose an answer, the model often breaks the user's prompt into a set of smaller sub-questions, retrieves information for each, and synthesizes a response. Being cited means your content was the best available source for one of those sub-questions. (We go deeper on the distinction in our post on GEO vs traditional SEO.)
This has three practical consequences:
- The unit of optimization is the sub-question, not the keyword. You're writing to satisfy a specific informational need the model is trying to fill.
- Structure matters more than length. Models favor content that states a clear, self-contained answer near a clearly labeled question. The Princeton research found passage-level structure and the addition of citations and statistics were among the most effective tactics.
- The scoreboard is different. Clicks and impressions in Google Search Console won't show you this growth. You need to measure citations and crawl activity directly.
If you measure GEO with SEO dashboards, the growth is essentially invisible. That mismatch is why a lot of teams underinvest in it.
The 3-step process we used
The most important thing to know up front: we didn't over-engineer this. The entire goal was a process simple enough to run every week — a system we could repeat, not a clever one-off.
Step 1: Build a prompt strategy
We weren't hunting for one "golden prompt" that unlocks everything. Instead, we tracked a portfolio of prompts and sorted them into three categories, each set up as its own Monitor in Promptwatch:
- Organic prompts (≈80%). These are about the category itself — the problems potential customers face and the questions an industry asks. Critically, they contain no brand or competitor names. This is the bulk of the strategy because it's where net-new citation growth comes from.
- Branded prompts (≈10%). A small set to keep a pulse on how AI describes our brand and the sentiment around it.
- Competitor prompts (≈10%). To understand how competitors are framed in AI answers and to spot coverage gaps we could fill to influence the organic and branded categories.
The 80/10/10 split is the key decision here. Most of your effort should go toward the organic category, because that's the demand that exists independently of whether anyone already knows your brand.
Step 2: Analyze the query fan-outs
A query fan-out (QFO) is the set of sub-questions an LLM generates and resolves internally before answering a prompt. A single prompt like "how do I improve AI search visibility" might fan out into "what is generative engine optimization," "how do LLMs choose sources," "what metrics measure AI visibility," and several more. These fan-outs are where the real content topics live.
Once we had a few days of response data in the organic Monitor, we analyzed every QFO attached to those prompts. We used the Promptwatch MCP inside an LLM to pull and read the fan-outs at scale, looking for patterns:
- Which sub-question phrasings repeat across many different prompts.
- The average number of fan-outs per prompt (a rough proxy for how complex the topic is).
- Clusters of related sub-questions that could be answered by a single, well-structured piece.
The repeating sub-questions are not a brainstorm — they're a demand-validated content brief. If the same sub-question surfaces across dozens of prompts, content that answers it cleanly has many chances to be retrieved.
Step 3: Publish, then measure and optimize
We wrote content built around those recurring themes — each piece structured to answer the specific sub-questions models kept resolving — and published.
Then we tracked two things for every piece:
- Time to crawl. How long until AI crawlers fetched the page. (AI bots like GPTBot and PerplexityBot don't show up in standard analytics)
- Time to cite. How long until the page started appearing as a source in answers.
From there the rule was simple: the content that earned citations first, we doubled down on — producing more in that format and topic cluster. The content that didn't get cited, we igored it and moved on. No sunk-cost rewrites. Effort moved to what was already working.
That feedback loop — track, analyze, publish, measure, optimize — is the entire engine. Run continuously this experiment, it's what compounds daily citations over time.
How do you measure AI citations and crawl activity?
You can't manage what you can't see, and standard analytics won't show citations. To run this process you need visibility into three things:
- Citations over time, ideally broken down by model (ChatGPT vs. Perplexity vs. Claude vs. Copilot), so you know which engines are picking you up.
- AI crawler logs, so you can see when bots like GPTBot or PerplexityBot fetch a page — this is your leading indicator before a citation ever appears.
- Prompt-level tracking, so you can connect a published page back to the specific prompts and fan-outs it was meant to serve.
Promptwatch is built around this exact measurement stack — Monitors for prompt tracking, query fan-out analysis, citation reporting by model, and crawler logs — which is what made the loop above possible to run and verify. If you're looking for options of AI SEO tools, our comparison of the top GEO and AI visibility platforms lays out how the major tools stack up.
How long does it take to see results?
It varies by page and by model, but the pattern we observed was: crawl first, citation second, with a lag of days to a few weeks between the two. New, well-structured pages that answered a high-frequency sub-question tended to get crawled quickly and cited soon after. Pages that targeted thinner or lower-frequency sub-questions often got crawled but never cited — which is exactly the signal we used to prune them.
The 200-to-1,700 climb happened over roughly three months of running this loop weekly. It was not a single spike; it was a series of compounding wins as more cited pages accumulated and we kept reallocating effort toward what worked.
Key takeaways
- GEO is not SEO. You're optimizing to be the source an AI answer is built from, not to win a click on a results page.
- Organic-first prompt strategy. An 80/10/10 split (organic / branded / competitor) puts most of your effort where net-new citation demand actually is.
- Query fan-outs are your content brief. Recurring sub-questions across prompts tell you exactly what to write — no guessing.
- Measure citations, not clicks. Track time-to-crawl and time-to-cite, double down on cited content, and prune the rest.
- Keep it simple and repeat it. The loop's power comes from running it every week, not from complexity.
Want to run this process on your own domain? Promptwatch gives you the prompt Monitors, query fan-out analysis, per-model citation reporting, and crawler logs to do it — plus a Content Agent that drafts content directly from your fan-outs and publish it directly on your website. Start tracking your citations today.

